Practical Architectures and CAD Tools for Streaming and Reconfigurable Computing

| Pipelining Commodity FPGAs: Practical Architectures and CAD Tools for Streaming and Reconfigurable Computing |
|
This project is an effort of ACME Labs within the EE Department of the University of Washington . The goal of this project is to develop new FPGA architecture and CAD tool approaches that benefit heavily pipelined streaming or reconfigurable computing applications while preserving the general-purpose usability of conventional reconfigurable devices.
Motivation
Although there can be significant overhead when mapping applications to FPGAs, research into reconfigurable computing platforms have shown that the flexibility, ease of programming, and ability to reuse silicon can allow developers to leverage the power of application-specialized hardware without the long design time and cost of ASICs.
Unfortunately, one of the largest limiting factors FPGA still have is limited clock frequency. Application developers often would like to compensate for this by heavily C-slowing or retiming their circuits when possible.This holds especially true in streaming or reconfigurable computing applications where latency can be less important than throughput. However, these techniques can create an enormous number of registers and the reconfigurable fabric itself, not to mention the compilation tools, must be able to handle this demand for pipelining resources.
Pipelined Hardware Support
The inclusion of specialized resources for the express purpose of supporting heavy pipelining is not a new idea. For example, the CLBs in Xilinx Virtex series devices have additional hardware that can transform the customary 4-LUT into a 16-bit shift register (Figure 1). However, although these capabilities are useful for I/O buffering and many DSP applications, these resources do not necessarily help us increase the operating frequency of mapped applications. This is because to pipeline long paths effectively, we might use many registers, but they need to be distributed evenly between the endpoints, not clustered together all in one CLB.
Figure 1: Many architectures allow memory cells within a
LUT to be used as a shift register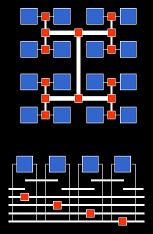
Figure 2:
HSRA[1] (top)
RaPiD[2] (bottom)Thus, for the most part, heavily pipelined circuits must make due with whatever flip flops happen to be available in the system. Even though many commercial FPGA architectures allow logic blocks to use embedded flip-flops to register signals independent of the logic mapped to the LUTs, finding enough free flip-flops can be a challenge. Furthermore, this setup does not address the primary contributor to delay in modern FPGAs – the interconnect.
Many academic research efforts have attempted to address the issue of interconnect delay and the needs of heavily pipelined netlists by designing specialized pipelined-interconnect architectures. As shown in Figure 2, these devices distinguish themselves from conventional FPGAs by including separate registering resources embedded directly in the communication network itself. HSRA [1] and RaPiD [2] are good examples of this approach. Unfortunately, while these research efforts have produced some promising results for heavily pipelined circuits, they have not become very popular. This is because the design of these architectures typically causes serious logic density and mapping problems for general-purpose, non-heavily pipelined netlists. Since commercial FPGA manufacturers must design their devices for the needs of average users, the devices that reconfigurable or stream computing application developers really want never get the advantages of mass-market fabrication.
Proposed Architecture Work
We propose a fundamentally different approach to developing reconfigurable architectures for heavily pipelined applications. Here, we concede that commercially successful devices must maintain most of the logic density and timing of conventional architectures for generic netlists. Instead, we propose the question: “If we were to allow a relatively negligible 1 to 2% degradation in area or timing for general-purpose circuits, what features could we include that would benefit heavily pipelined applications?” Granted, we may not achieve the exceptionally high efficiency of extremely customized streaming or reconfigurable computing architectures, but we would also not inherit their shortcomings. Could we develop a commercially viable system that would provide resources good for heavily-pipelined applications without alienating users that did not need these features?
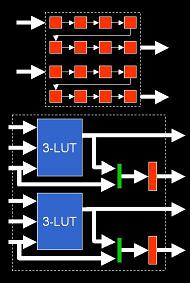
Figure 3: Enhancing existing shift register modes (top) or replacing standard 4-LUT + FF with two 3-LUTs + FFs (bottom) 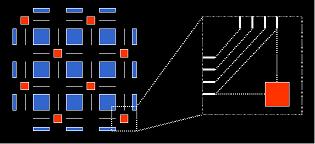
Figure 4: Interconnect registers Modify Logic Blocks: Since the logic blocks themselves comprise a relatively small portion of the overall area in modern FPGAs, this is likely a good starting point. As seen in Figure 3, with a few extra configuration bits and some multiplexing we can improve the usability of logic block shift-register modes by splitting the chain into multiple parts. Another possibility is that we could replace the customary one 4-LUT and a flip-flop with two sets of 3-LUTs and flip-flops. Perhaps this is too aggressive a modification, but there is a whole host of ways to add independent flip-flops into logic blocks without seriously affecting general-purpose usability.
Pipeline Interconnect: However, another important issue is how to pipeline the interconnect. Since the interconnect is responsible for both the majority of the area and delay in modern devices, pipelining the interconnect is likely highly advantageous for both heavily pipelined and general-purpose applications, but any modifications we make need to be done very carefully. As seen in Figure 4, one possible scenario would make an optional register available on a small number of tracks across the architecture. A small fraction of pipelined lines will have a minimal impact on non-pipelined netlists, but we can greatly improve the availability of registers to netlists that need them.
Proposed CAD Tool Support
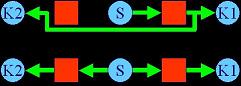
Figure 5: One register leads to a long path (top)
Duplicating the register can help the system (bottom)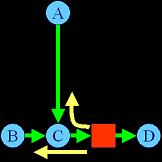
Figure 6: Retiming can push registers from the output to the input of a node Unfortunately, while these modifications can dramatically improve the performance of heavily pipelined netlists, this also creates some unique CAD problems.
Mapping: First, this complicates the mapping problem. Now there are multiple different ways for a netlist to pick up registers: turn unused LUTs into shift registers, utilize flip-flops embedded in logic blocks, and pick up registers in the interconnect. Which resource is best suited for a given pipelined net depends not only upon the total number of registers the net requires, but also the difference in latency between multiple sinks and the distance the net must span. If the source and sink are very far from one another we need to space out the registers evenly. If this signal is timing critical, we may even elect to use registers within the interconnect to avoid the delay of going into and out of a logic block. If the source and sink happen to be very close to each other, but the signal has a high pipelining latency (this often happens when short signals are forced to have extra registers to balance those pushed onto long signals), it might be better to map these registers into an unused LUT turned shift register. However, this means that the mapping of registers must really be done as a part of placement.
Placement: That said, even if we uncover all registers in the system and place a netlist at the flip-flop level we still have further issues to address. First, we must consider when register duplication is a good idea. As seen in Figure 5, we may have pipelined sinks that wish to go in opposite directions (K1, K2) with respect to the source (S). If we have sufficient registers in the architecture, we should not have to create a long wire between the register and K2, we should be able to “unzip” the pipelined signal and duplicate pipelining registers. Considering the number of deeply pipelined signals we might encounter in reconfigurable or stream computing applications, performing this register duplication in a responsible manner with respect to available resources and critical path timing will be difficult. Second, we must also consider when retiming is a good idea. As seen in Figure 6, after the majority of the placement has been settled we may realize that certain signals have been made unnecessarily long. If suitable registers were available, we could retime this netlist and move the register to the inputs of node C (register the paths from A->C and B->C instead of C->D). This would likely achieve better timing. However, again, this problem is difficult given the number of potential pipelined signals. We propose to incorporate register duplication and retiming as part of a timing-driven simulated annealing tool.
Routing: Finally, it is likely that the inclusion of interconnect registers will have a dramatic effect on routing capabilities. Although we will likely assign registers during the placement process to get a rough idea regarding register availability versus demand, we may not want to make this register placement absolutely binding during the routing stage. Not only is there the issue of congestion and, thus, some degree of timing uncertainty at placement time, registers embedded in the interconnect present an unusually difficult problem. As seen in Figure 7, due to area concerns registers inside the routing network generally have very little or no flexibility in the connectivity. This means that determining where a signals registers should be during placement also might determine the majority of a signals routing during placement. Thus, to maintain the routability of deeply pipelined netlists we must assign registers as part of the routing process. Unfortunately, as seen in [SHARMA03], this dramatically changes the overall routing problem.
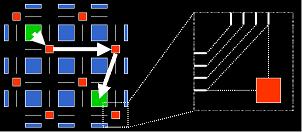
Figure 7: Since register embedded in the interconnect have limited connectivity, assigning a signal to use a specific pipelining register can essentially fix a portion of the routing of that signal Now, instead of merely finding the shortest path between a source and sink we need to find a path that goes through exactly N registers. This prevents us from using the classical Dijkstra’s search and lead to the development of PipeRoute. However, since we pipelined both the netlists and the architectures due to timing concerns, a timing-driven router would be nice. That said, as seen in [EGURO06], further investigation found that not only were customary search techniques inadequate for congestion-driven pipelined routing, conventional timing-driven cost formulations caused serious timing oscillations for timing-driven pipelined routing. This lead to the development of Armada.
Researchers
This effort is headed by Scott Hauck, Professor in the EE Department at University Washington, and director of ACME Labs.Other researchers include:
- Ken Eguro, Microsoft Research
- Akshay Sharma, University of Washington
This research was funded in part by the National Science Foundation under Grant #CCF0426147
A. Sharma, C. Ebeling, S. Hauck, "PipeRoute: A Pipelining-Aware Router for Reconfigurable Architectures", IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, Vol. 25, No. 3, pp. 518-532, March 2006.
A. Sharma, Place and Route Techniques for FPGA Architecture Advancement, Ph.D. Thesis, University of Washington, Dept. of EE, 2005.
K. Eguro, Supporting High-Performance Pipelined Computation in Commodity-Style FPGAs, Ph.D. Thesis, University of Washington, Dept. of EE, 2008.
A. Sharma, C. Ebeling, S. Hauck, "PipeRoute: A Pipelining-Aware Router for FPGAs", ACM/SIGDA Symposium on Field-Programmable Gate Arrays , pp. 68-77, 2003.
A. Sharma, K. Compton, C. Ebeling, S. Hauck, "Exploration of Pipelined FPGA Interconnect Structures", ACM/SIGDA Symposium on Field-Programmable Gate Arrays , pp. 13-22, 2004.
K. Eguro, S. Hauck, A. Sharma, "Architecture-Adaptive Range Limit Windowing for Simulated Annealing FPGA Placement", Design Automation Conference, pp. 439-444, 2005.
K. Eguro, S. Hauck, "Armada: Timing-Driven Pipeline-Aware Routing for FPGAs", ACM/SIGDA Symposium on Field-Programmable Gate Arrays, pp. 169-178, 2006.
Ken Eguro, Scott Hauck, "Simultaneous Retiming and Placement for Pipelined Netlists", IEEE Symposium on Field-Programmable Custom Computing Machines, pp. 139-148, 2008.Ken Eguro, Scott Hauck, "Enhancing Timing-Driven FPGA Placement for Pipelined Netlists", Design Automation Conference, pp. 34-37, 2008.
A. Sharma, C. Ebeling, S. Hauck, "PipeRoute: A Pipelining-Aware Router for FPGAs", University of Washington, Dept. of EE Technical Report UWEETR-2002-0018 , 2002.
A. Sharma, K. Compton, C. Ebeling, S. Hauck, "Exploration of RaPiD-style Pipelined FPGA Interconnects", 2004.
